合并节点#
使用合并节点将来自多个数据流的数据进行组合,当所有数据流的数据都可用时执行合并。
0.194.0 版本重大变更
n8n 团队在 n8n 0.194.0 版本中彻底重构了此�节点。本文档反映的是该节点的最新版本。如果您使用的是旧版 n8n,可以在此处找到本文档的先前版本。
1.49.0 版本次要变更
n8n 1.49.0 版本引入了添加两个以上输入的功能。旧版本仅支持最多两个输入。如果您运行的是旧版本,并希望在这些版本中合并多个输入,请使用代码节点。
模式 > SQL 查询功能也是在 n8n 1.49.0 版本中添加的,旧版本中不可用。
节点参数#
您可以通过选择模式来指定合并节点应如何组合来自不同数据流的数据:
追加#
保留所有输入的数据。选择输入数量以逐个输出每个输入的数据项。节点会等待所有连接的输入执行完毕。

追加模式输入和输出
组合#
组合两个输入的数据。在组合方式中选择一个选项,以确定您希望如何合并输入数据。
匹配字段#
按字段值比较数据项。在要匹配的字段中输入您要比较的字段。
n8n 的默认行为是保留匹配项。您可以使用输出类型设置更改此行为:
- 保留匹配项:合并匹配的数据项。这类似于内连接。
- 保留非匹配项:合并不匹配的数据项。
- 保留所有项:合并匹配的数据项,并包含不匹配的数据项。这类似于外连接。
- 丰富输入 1:保留输入 1 的所有数据,并添加来自输入 2 的匹配数据。这类似于左连接。
- 丰富输入 2:保留输入 2 的所有数据,并添加来自输入 1 的匹配数据。这类似于右连接。

按匹配字段组合模式输入和输出
位置#
根据数据项的顺序进行组合。输入 1 中索引为 0 的数据项与输入 2 中索引为 0 的数据项合并,依此类推。

按位置组合模式输入和输出
所有可能组合#
输出所有可能的数据项组合,同时合并同名字段。

按所有可能组合模式输入和输出
组合模式选项#
当通过模式 > 组合合并数据时,您可以设置以下选项:
- 冲突处理:选择当数据流冲突或存在子字段时如何合并。详情请参阅冲突处理。
- 模糊比较:在比较字段时是否容忍类型差异(启用),或者不容忍(禁用,默认)。例如,当您�启用此选项时,n8n 会将
"3"和3视为相同。 - 禁用点表示法:这可以防止在字段名称中使用
parent.child来访问子字段。 - 多重匹配:选择 n8n 在比较数据流时如何处理多重匹配。
- 包含所有匹配项:如果存在多个匹配项,则输出多个数据项,每个匹配项一个。
- 仅包含第一个匹配项:保留每个匹配项的第一个数据项,并丢弃其余的多重匹配项。
- 包含任何未配对项:选择在按位置合并时是保留还是丢弃未配对的数据项。默认行为是排除没有匹配项的数据项。
冲突处理#
如果某个索引处的多个数据项具有同名字段,则会发生冲突。例如,如果输入 1 和输入 2 中的所有数据项都有一个名为 language 的字段,则这些字段会发生冲突。默认情况下,n8n 会优先处理输入 2,这意味着如果 language 在输入 2 中有值,n8n 在合并数据项时会使用该值。
您可以通过选择选项 > 冲突处理来更改此行为:
- 当字段值冲突时:选择要优先处理哪个输入,或者选择始终将输入编号添加到字段名称以保留所有字段和值,并在字段名称后附加输入编号以显示其来源。
- 合并嵌套字段
- 深度合并:合并数据项所有层级的属性,包括嵌套对象。这在处理复杂的嵌套数据结构时非常有用,因为您需要确保合并所有层级的嵌套属性。
- 浅层合并:仅合并数据项顶层的属性,不合并嵌套对象。这在您拥有扁平数据结构或仅需要合并顶层属性而不关心嵌套属性时非常有用。
SQL 查询#
编写自定义 SQL 查询来合并数据。
示例:
SELECT * FROM input1 LEFT JOIN input2 ON input1.name = input2.id
先前节点的数据以表格形式提供,您可以在SQL查询中按顺序将其用作input1、input2、input3等输入参数。完整支持的SQL语句列表请参阅AlaSQL GitHub页面。
选择分支#
选择要保留的输入源。此选项会持续等待直至两个输入源的数据均准备就绪。您可选择输出:
- 输入1数据
- 输入2数据
- 单一空项
该节点将输出所选输入源的数据且不作任何修改。
模板与示例#
使用AI抓取并摘要网页
由n8n团队提供
查看模板详情
通过Seedance生成AI病毒视频并上传至TikTok、YouTube和Instagram
由Firas博士提供
查看模板详情
✨🤖 使用AI实现多平台社交媒体内容创作自动化
由Joseph LePage提供
查看模板详情
合并条目数不均的数据流#
传入Merge节点输入1的条目将优先处理。例如,若Merge节点在输入1收到5个条目,在输入2收到10个条目,则仅处理5个条目。输入2中剩余的5个条目将不被处理。
使用If节点与Merge节点的分支执行#
0.236.0及更早版本
n8n在1.0版本移除了此执行行为。本节适用于使用v0(旧版) 工作流执行顺序的工作流。默认情况下,所有1.0版本之前构建的工作流均属此类。您可在工作流设置中更改执行顺序。
若在包含If节点的工作流中添加Merge节点,可能导致If节点的两个输出数据流均被执行。
一个数据流会触发Merge节点,继而执行另一个数据流。
例如,下方截图中的工作流包含编辑字段节点、If节点和Merge节点。If节点的标准行为是执行单个数据流(截图中为true输出)。但由于Merge节点的存在,即使If节点未向false数据流发送任何数据,两个数据流仍会被执行。
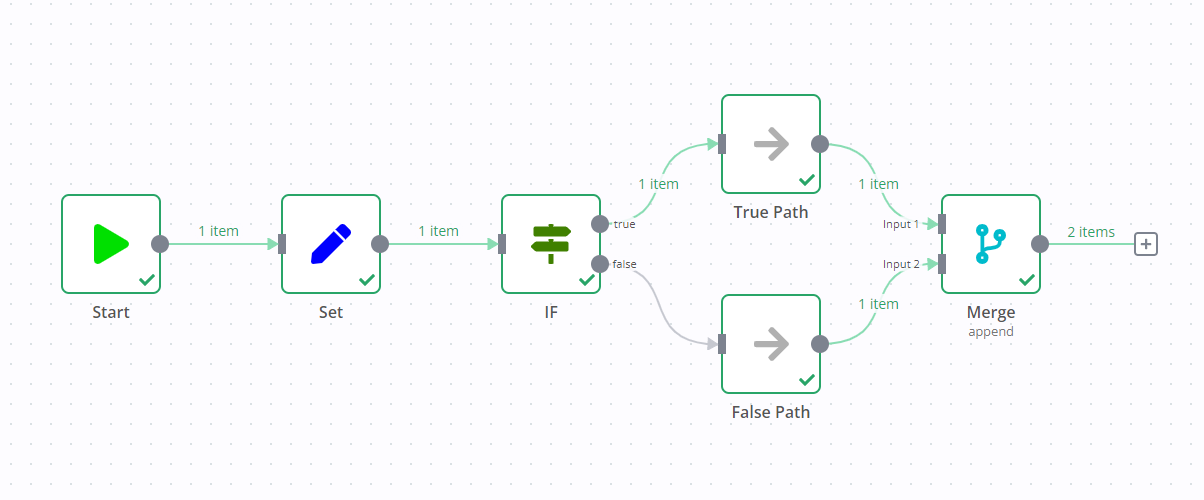
实践演练:分步示例#
创建包含示例输入数据的工作流来体验Merge节点功能。
使用代码节点设置示例数据#
- 在画布添加代码节点并将其连接到起始节点
- 在JavaScript代码字段粘贴以下代码片段:
return [ { json: { name: 'Stefan', language: 'de', } }, { json: { name: 'Jim', language: 'en', } }, { json: { name: 'Hans', language: 'de', } } ];
- 添加第二个代码节点,并将其连接到起始节点。
- 在 JavaScript 代码 字段中粘贴以下 JavaScript 代码片段:
return [ { json: { greeting: 'Hello', language: 'en', } }, { json: { greeting: 'Hallo', language: 'de', } } ];
尝试不同合并模式#
添加合并节点。将第一个代码节点连接至输入1,第二个代码节点连接至输入2。运行工作流将数据载入合并节点。
最终工作流应如下所示:
现在尝试模式中的不同选项,观察其对输出数据的影响。
追加模式#
选择模式 > 追加,然后选择执行步骤。
表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候语 |
|---|---|---|
| Stefan | de | |
| Jim | en | |
| Hans | de | |
| en | Hello | |
| de | Hallo |
按字段匹配合并#
您可以通过合并两个数据输入,使每个人获得对应语言的正确问候语。
- 选择模式 > 组合
- 选择组合方式 > 字段匹配
- 在输入1字段和输入2字段中均输入
language,这将指示n8n通过匹配各数据集中language字段的值来组合数据 - 选择执行步骤
表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候语 |
|---|---|---|
| Stefan | de | Hallo |
| Jim | en | Hello |
| Hans | de | Hallo |
按位置合并#
选择模式 > 组合,组合方式 > 位置,然后选择执行步骤。
表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候语 |
|---|---|---|
| Stefan | en | Hello |
| Jim | de | Hallo |
保留未匹配项#
如需保留所有项目,请选择添加选项 > 包含未匹配项,然后开启包含未匹配项。
表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候语 |
|---|---|---|
| Stefan | en | Hello |
| Jim | de | Hallo |
| Hans | de |
全组合合并#
选择模式 > 组合,组合方式 > 全组合,然后选择执行步骤。
表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候语 |
|---|---|---|
| Stefan | en | Hello |
| Stefan | de | Hallo |
| Jim | en | Hello |
| Jim | de | Hallo |
| Hans | en | Hello |
| Hans | de | Hallo |