数据合并与拆分#
本章将学习如何合并与拆分数据,以及在哪些场景下执行这些操作具有实际价值。
数据合并#
某些场景下可能需要合并(组合)并处理来自不同数据源的信息。
数据合并可能涉及:
- 基于多数据源创建统一数据集
- 在多系统间实现数据同步,包括清除重复数据或当主系统数据变更时同步更新其他系统
单向同步与双向同步
在单向同步中,数据仅沿单一方向同步。某个系统作为唯一可信数据源,当主系统信息变更时,次级系统会自动更新;但若次级系统发生数据变更,则不会反馈至主系统。
在双向同步中,数据在双系统间实现双向同步。任一系统的数据变更都会自动同步到另一系统。
这篇博客教程详细讲解了如何在两个CRM系统间实现单向与双向数据同步。
在n8n中,可通过合并节点融合来自两个不同节点的数据,该节点提供多种合并模式:
注意:组合模式下的字段匹配合并需要指定用于比对的输入字段。这些字段应在不同数据源中包含完全一致的值,以确保n8n能准确实现数据匹配。在合并节点中,这些字段被命名为Input 1 Field和Input 2 Field。

合并节点中的属性输入字段
点标记法属性输入
若需在合并节点的Input 1 Field和Input 2 Field参数中引用嵌套值,必须以点标记格式输入属性键(需以文本形式输入,不可使用表达式)。
注意
合并节点在界面中也可能显示为"连接"别名。若您熟悉SQL连接操作,这个名称可能更直观。
合并实操练习#
构建一个合并客户数据存储节点与代码节点数据的工作流:
- 添加合并节点,其
Input 1连接至客户数据存储节点,Input 2连接至代码节点 - 在客户数据存储节点中运行获取所有人员操作
- 在代码节点中创建包含两个对象的数组,每个对象需包含
name、language和country三个属性,其中country属性应包含code和name两个子属性- 使用客户数据库中的两个角色信息填充这些属性值
- 例如:杰伊·盖茨比的语言为英语,国家名称为美国
- 在合并节点中尝试不同合并选项
查看参考解决方案
本练习的工作流结构如下:

数据合并练习工作流
若选择保留匹配项合并选项并以姓名字段作为匹配依据,输出结果示例如下(注意此示例仅显示杰伊·盖茨比,实际结果因选择角色而异):
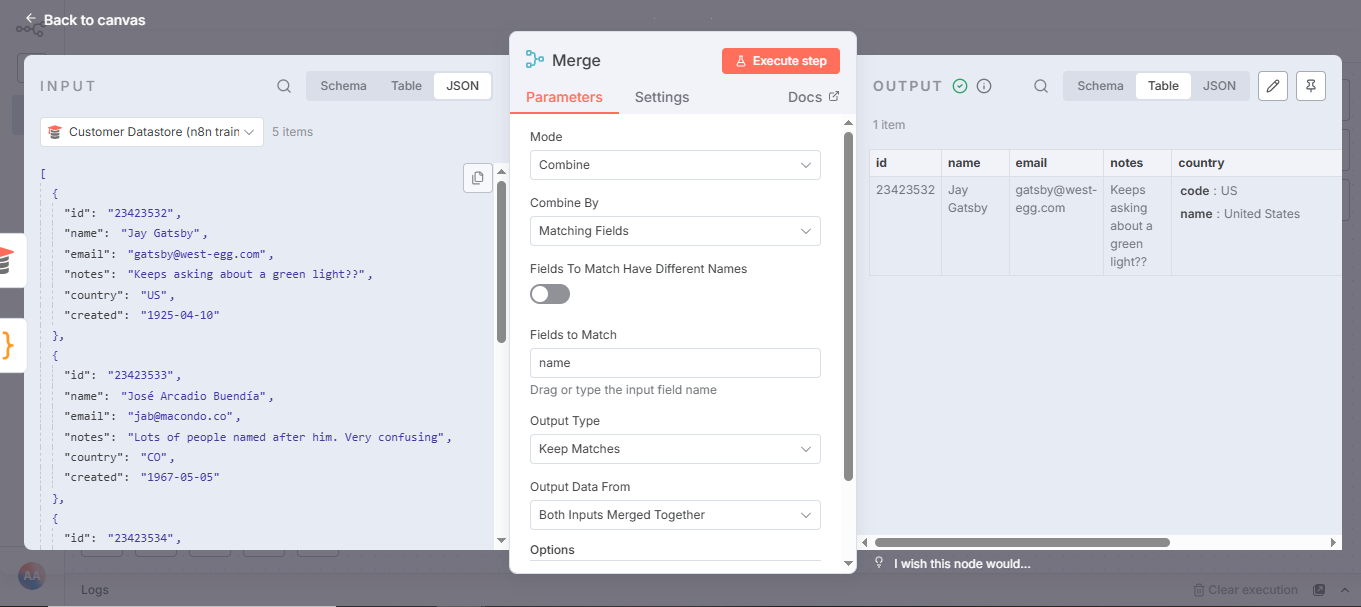
保留匹配项合并节点的输出结果
如需查看节点配置详情,可复制下方JSON工作流代码并粘贴至编辑器界面:
{
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "cb484ba7b742928a2048bf8829668bed5b5ad9787579adea888f05980292a4a7"
},
"nodes": [
{
"parameters": {
"mode": "combine",
"mergeByFields": {
"values": [
{
"field1": "name",
"field2": "name"
}
]
},
"options": {}
},
"id": "578365f3-26dd-4fa6-9858-f0a5fdfc413b",
"name": "Merge",
"type": "n8n-nodes-base.merge",
"typeVersion": 2.1,
"position": [
720,
580
]
},
{
"parameters": {},
"id": "71aa5aad-afdf-4f8a-bca0-34450eee8acc",
"name": "When clicking \"Execute workflow\"",
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
260,
560
]
},
{
"parameters": {
"operation": "getAllPeople"
},
"id": "497174fe-3cab-4160-8103-78b44efd038d",
"name": "Customer Datastore (n8n training)",
"type": "n8n-nodes-base.n8nTrainingCustomerDatastore",
"typeVersion": 1,
"position": [
500,
460
]
},
{
"parameters": {
"jsCode": "return [\n {\n 'name': 'Jay Gatsby',\n 'language': 'English',\n 'country': {\n 'code': 'US',\n 'name': 'United States'\n }\n \n }\n \n];"
},
"id": "387e8a1e-e796-4f05-8e75-7ce25c786c5f",
"name": "Code",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
500,
720
]
}
],
"connections": {
"When clicking \"Execute workflow\"": {
"main": [
[
{
"node": "Customer Datastore (n8n training)",
"type": "main",
"index": 0
},
{
"node": "Code",
"type": "main",
"index": 0
}
]
]
},
"Customer Datastore (n8n training)": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 0
}
]
]
},
"Code": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 1
}
]
]
}
},
"pinData": {}
}
循环操作#
某些情况下,您可能需要对数组中的每个元素或每条数据执行相同操作(例如向通讯录中��的每个联系人发送消息)。用技术术语来说,您需要遍历数据(通过循环)。
n8n 通常会自动处理这种重复性操作,因为节点会对每个数据项执行一次,因此您无需在工作流中构建循环。
但存在一些节点和操作例外情况,需要您在工作流中构建循环。
若要在 n8n 工作流中创建循环,您需要将某个节点的输出连接到前序节点的输入,并添加 If 节点 来判断何时终止循环。
数据分批处理#
当需要处理海量输入数据、多次执行 Code 节点 或规避 API 速率限制时,最佳实践是将数据分割为批次(组)并逐批处理。
此类处理建议使用 Loop Over Items 节点。该节点会将输入数据按指定批次大小分割,并在每次迭代时返回预设数量的数据。
Loop Over Items 节点执行机制
Loop Over Items 节点 会在所有输入项完成分批并传递至工作流下一节点后自动停止执行,因此无需额外添加 If 节点 来终止循环。
循环/分批练习#
构建一个可读取 Medium 和 dev.to 的 RSS 源的工作流。该工作流应包含三个节点:
- 一个返回 Medium (
https://medium.com/feed/n8n-io) 和 dev.to (https://dev.to/feed/n8n) RSS 源 URL 的 Code 节点。 - 一个设置
批次大小:1的 Loop Over Items 节点,用于接收 Code 节点 和 RSS Read 节点 的输入并遍历数据项。 - 一个通过表达式
{{ $json.url }}获取 Medium RSS 源 URL 的 RSS Read 节点。- RSS Read 节点 属于例外节点,仅处理接收到的首条数据项,因此需使用 Loop Over Items 节点 来实现多数据项遍历。
查看解决方案
- 添加 Code 节点,可通过多种方式编写代码,例如:
- 将 模式 设置为
对所有项运行一次 - 将 语言 设置为
JavaScript - 复制以下代码粘贴至 JavaScript 代码编辑器:
- 将 模式 设置为
let urls = [
{
json: {
url: 'https://medium.com/feed/n8n-io'
}
},
{
json: {
url: 'https://dev.to/feed/n8n'
}
}
]
return urls;
- 将 Loop Over Items 节点 连接到 Code 节点。
- 将 Batch Size 设置为
1。
- 将 Batch Size 设置为
- Loop Over Items 节点 会自动添加一个名为 "Replace Me" 的节点。将该节点替换为 RSS Read 节点。
- 将 URL 设置为使用来自 Code 节点的 URL:
{{ $json.url }}。
- 将 URL 设置为使用来自 Code 节点的 URL:
本练习的工作流如下所示:

从两个博客获取 RSS 订阅源的工作流
要检查节点的配置,您可以复制下面的 JSON 工作流代码,并将其粘贴到您的编辑器界面中:
{
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "cb484ba7b742928a2048bf8829668bed5b5ad9787579adea888f05980292a4a7"
},
"nodes": [
{
"parameters": {},
"id": "ed8dc090-ae8c-4db6-a93b-0fa873015c25",
"name": "When clicking \"Execute workflow\"",
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
460,
460
]
},
{
"parameters": {
"jsCode": "let urls = [\n {\n json: {\n url: 'https://medium.com/feed/n8n-io'\n }\n },\n {\n json: {\n url: 'https://dev.to/feed/n8n'\n } \n }\n]\n\nreturn urls;"
},
"id": "1df2a9bf-f970-4e04-b906-92dbbc9e8d3a",
"name": "Code",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
680,
460
]
},
{
"parameters": {
"options": {}
},
"id": "3cce249a-0eab-42e2-90e3-dbdf3684e012",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
900,
460
]
},
{
"parameters": {
"url": "={{ $json.url }}",
"options": {}
},
"id": "50e1c1dc-9a5d-42d3-b7c0-accc31636aa6",
"name": "RSS Read",
"type": "n8n-nodes-base.rssFeedRead",
"typeVersion": 1,
"position": [
1120,
460
]
}
],
"connections": {
"When clicking \"Execute workflow\"": {
"main": [
[
{
"node": "Code",
"type": "main",
"index": 0
}
]
]
},
"Code": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
null,
[
{
"node": "RSS Read",
"type": "main",
"index": 0
}
]
]
},
"RSS Read": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {}
}